On Screen Reader Detection
Background
The latest WebAIM screen reader survey results came out last week, and I had been looking forward to the results of the questions related to screen reader detection. I can say I was a bit surprised by both. To make it easy, I’ll reprint the questions and answers here.
Screen Reader Detection
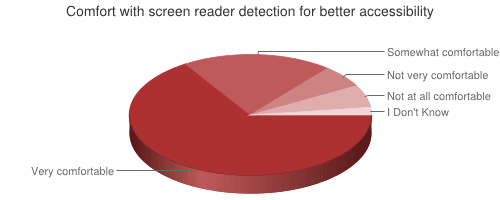
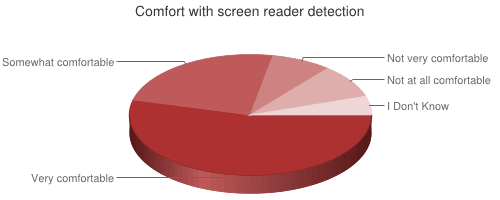
How comfortable would you be with allowing web sites to detect whether you are using a screen reader? (See the question on the WebAIM site.)
The vast majority (78.4%) of screen reader users are very or somewhat comfortable with allowing screen reader detection. 55.4% of those with disabilities indicated they were very comfortable with screen reader detection compared to 31.4% of respondents without disabilities.
Screen Reader Detection for Better Accessibility
How comfortable would you be with allowing web sites to detect whether you are using a screen reader if doing so resulted in a more accessible experience? (See the question on the WebAIM site.)
86.5% of respondents were very or somewhat comfortable with allowing screen reader detection if it resulted in better accessibility. Historically, there has generally been resistance to web technologies that would detect assistive technologies – primarily due to privacy concerns and fear of discrimination. These responses clearly indicate that the vast majority of users are comfortable with revealing their usage of assistive technologies, especially if it results in a more accessible experience.
My Opinion
I think the wrong question is being asked on the survey.
Detecting a screen reader is akin to detecting a browser. If you’ve been doing this long enough, you know that on the whole browser detection is a bad idea. It is often wrong and doesn’t necessarily equate to what features really exist, which is why feature detection evolved as a best practice. You can read my rant from 2011 where web devs were making the same mistake trying to detect mobile devices.
Detecting the features of a screen reader is different, however. Here you may be able to actually get somewhere. But this is where different risks come in. I’ll focus on three that come to mind immediately.
Double Effort
The first is what happens once you have detected a user with a screen reader. Do you detect for other accessibility tools or ignore those? Do you serve different content? Different mark-up? Do users get shunted to different URLs?
Evidence suggests this doesn’t ever go well. Even today, the example of the UK Home Office Cyber Streetwise site is perfect example — the user is provided a link that cannot be activated sans mouse which in turn points to a text-only version of the site. It is not truly accessible and assumes only visual disabilities.
Any organization charged with maintaining two sites will ultimately fail at doing so as resources are prioritized to targeting the primary site. Eventually you get an atrophied site in the best case, and a complete failure in the worst case.
It opens the door to separate-but-equal thinking. Patrick Lauke captured this idea nicely on Twitter, which I re-tweeted with this longdesc (because I am that guy):
Longdesc: Small water fountain labeled "Accessible version" next to big labeled "Regular site." RT @patrick_h_lauke: pic.twitter.com/dHeod8SN1H
— Adrian Roselli (@aardrian) February 21, 2014Selection Bias
A second risk with this detection approach is that selection bias will taint your perspective (I’ve written about this before). Just as web devs would build features that blocked, say IE6, and then turn around to point out that IE6 usage had dropped on their sites, we can expect to see the same thing happen here.
Poorly-written detection scripts will set the expectation that site owners are getting a view of who is using their site, but will end up showing the opposite. Not only that, low numbers can be used to justify not supporting those users, especially if those numbers come in below the IE6 or IE8 or whatever-is-the-current-most-hated-IE numbers that you’ve been arguing are too low to support. Roger Johansson sums it up nicely:
@mattmay @jared_w_smith It would likely be used to say "we've only had one SR using visitor the last month, so let's not bother".
— Roger Johansson (@rogerjohansson) March 2, 2014Privacy
We already know that assorted web beacons can cross-reference your social media profiles to your gender to your geographic location to your age to your shoe size. There is already plenty of personally-identifiable information about you available to every site, is it right to allow those sites to know you have a disability?
This is the kind of information that in the United States you might think is covered by HIPAA, only to find that as a general web surfer you are handing it over to anyone who asks. Certainly no registry can be trusted with managing that when even the UK’s NHS uploads not-really-anonymized patient data to the cloud (Google servers outside the UK in this case).
Consider also what happens when the site has a different URL for every page targeted specifically at disabled users. Now when those users share a URL to a page, they are in effect telling the world they have a disability, even if which disability isn’t clear.
There is a privacy risk here that I don’t think those who took the survey were in a position to consider, and I don’t those who asked the question were able to contextualize appropriately.
Other Responses
Marco Zehe jumps on this pretty quickly with his post Why screen reader detection on the web is a bad thing. In addition to raising points why he thinks this is bad, he points out where the survey takers might not understand the scope of the question:
Funny enough, the question about plain text alternatives was answered with “seldom or never” by almost 30% of respondents, so the desire to use such sites in general is much lower than the two screen reader detection questions might suggest. So I again submit that only the lack of proper context made so many people answer those questions differently than the one about plain text alternatives.
Léonie Watson also responded quickly in her post Thoughts on screen reader detection with her own reasons that I am breaking down into a bullet list here (on her post, these are the headings for copy with more detail):
- I don’t want to share personal information with websites I visit
- I don’t want to be relegated to a ghetto
- I don’t want design decisions to be based on the wrong thing
- I don’t want old mistakes to be repeated
- I don’t want things to be hard work
- I do want much more conversation about screen reader detection
Karl Groves points out some disability points the general public often forgets in hist post “Should we detect screen readers?” is the wrong question:
- There are more people who are low-vision than who are blind
- There are more people who are hard of hearing than who are visually impaired
- There are more people who are motor impaired than who are hard of hearing
- There are more people who are cognitively impaired than all of the above
Dennis Lembree covers reasons against over at WebAxe in the post Detecting Screen Readers – No
- Text-only websites didn’t work before and you know devs will do this if a mechanism is provided.
- Screen reader detection is eerily similar to the browser-sniffing technique which has proven to be a poor practice.
- Maintaining separate channels of code is a nightmare; developers overloaded already with supporting multiple browsers, devices, etc (via RWD). And if done, it will many times become outdated if not entirely forgotten about.
- Why screen reader detection? If you follow that logic, then detection should be provided for screen magnifiers, braille output devices, onscreen keyboards, voice-recognition, etc. That’s just crazy.
Dylan Barrell is (so far as I have found) the sole voice saying maybe this isn’t so bad, in hist post Assistive Technology Detection: It can be done right [Update, 24 April 2019: the blog is gone, and Wayback cannot load it, so I link to the Wayback summary page for those who can maybe get the raw page out of it.]. He argues for some benefits and then proposes a couple possible approaches to deal with the concerns he is hearing:
- Allow the web site to request the information, and the user to allow/disallow this on a per-website/domain basis. I.e. the web site requests and the user decides. […]
- A second approach is to put the control in the hands of a registry. This registry would store the domain names of the organizations who have signed a contract that explicitly binds them into a code of conduct regarding the use of the data. […]
Update: March 5, 2014
Marco Zehe, Mozilla accessibility QA engineer and evangelist, has opened a bug with Mozilla asking for a privacy review of the overall idea of screen reader detection: Bug 979298 – Screen reader detection heuristics: Privacy review
Update: March 6, 2014
Along the lines of separate-but-equal text-only sites being anything but equal, Safeway appears to have bought into that concept and is eliminating its text-only site in favor of making the overall site more accessible.
Update: March 19, 2014
In the post Am I Vision Impaired? Who Wants to Know? the author points out that by installing apps on your phone, you are already giving the app makers access to whether or not you use AT. There is an API for this information and its use is not indicated to end users that way the phone tells/asks you about access to your camera or GPS.
Update: April 17, 2016
If you still think that detecting screen readers, or any other assistive technology, is a good method to provide a customized interface to users, consider the examples I identified in my post Be Wary of Add-on Accessibility. While these are intended for users who self-identify as screen reader users, the outcome is the same — terrible. Let’s not forget that the Virgin America example was built by an accessibility tech company.
Update: August 9, 2016
In the post Detecting screen readers in analytics, Heather Burns essentially comes to the same conclusion:
[W]hen all the aspects of the issue are taken into consideration, screen reader detection emerges as a technique which carries serious technical, ethical and privacy risks. […] Added together, these factors create a gray area of risk, liability, and inconvenience which outweighs any good that the insights gained from the analytics might provide. On balance, then, the technique is sadly not worth adopting.
Update: May 7, 2017
In the most recent discussion of how and why you may want to detect users with disabilities, the conclusion is pretty clear. Just make all your stuff accessible.
Collectively, as a community, we have the potential to make a big difference on web accessibility for disabled users. As consultants, clients rely on us to make sound, educated decisions on their behalf about everything from analytics practices to good user experiences. It is our responsibility to create great digital accessibility experiences for every project we take on while helping our clients better understand the importance of these decisions.
Update: January 29, 2018
I like the idea behind the Accessibility Object Model (AOM), but I am concerned that it can be used to track users of assistive technology.
The draft specification for AOM acknowledges this in its own section on privacy:
To address these concerns, a web site should not be able to receive these events until the user has explicitly opted in to allow those events to be received by that web site.
The fallback would just be work as we do today, just lean on ARIA and HTML.
Update: January 31, 2018
Thanks to a post from Glenda Sims on the Web Accessibility Initiative (WAI) Interest Group (IG) list, I was reminded that the IndieUI proto-spec has a whole bit on screen reader detection:
One potential misuse is for user metrics or tracking. Even with the best of intentions, this is a potentially harmful misuse of the API. There are currently very strict user privacy model requirements to implement this feature in a reasonably safe and secure way, but if the working group is not comfortable in the implementation’s ability to sufficiently prevent this type of misuse, we will remove the feature.
In short, W3C recognizes and acknowledges the risk.
Update: March 27, 2019
Paul Adam found this gem from AppleVis (itself quoting Apple’s screen shot) about the new Accessibility Events which:
[…] allow websites to customize their behaviour for assistive technologies, like VoiceOver. Enabling Accessibility Events may reveal whether an assistive technology is active on your iPhone.
This feature is enabled by default. To disable it you must go to Settings > General > Accessibility > VoiceOver > Web.
Amanda Rush is one of many screen reader users who has come out against this feature, with others expressing their frustration on Twitter.
Update: March 30, 2019
Ashley Sheridan has added another voice to the mix in The Problem With Accessibility Events in iOS 12.2. Ashley points out that Apple’s recent decision to remove Do Not Track from Safari casts this latest move in more interesting light when you take the whole of digital fingerprinting into account.
Update: April 11, 2019
Mat Marquis wrote about Apple’s accessibility events at CSS Tricks, which gets far more traffic from people outside of the accessibility community. Mostly he covers the arguments in this and linked posts but frames it in the conversations he has had with clients and now will have with clients in light of Apple’s move.
Update: May 19, 2020
Don’t be Facebook. This thread demonstrates how to do screen reader detection wrong.
Facebook's new avatars "represent who you are" — unless you're Blind.
The devs exploit screen reader detection at launch to hide the avatar maker from Blind Voiceover users.
This encoded bias is frictionless, fast and enacted without consent.
Update: November 11, 2020
The W3C Technical Architecture Group has good overall guidance here:
The TAG are pleased to announce the newest release of our Web Platform Design Principles, a set of principles specification designers should keep in mind when adding new technologies to the web: w3.org/TR/design-principles/
My favorite part is § 2.7. Don’t reveal that assistive technologies are being used:
Make sure that your API doesn’t provide a way for authors to detect that a user is using assistive technology without the user’s consent.
The web platform must be accessible to people with disabilities. If a site can detect that a user is using an assistive technology, that site can deny or restrict the user’s access to the services it provides.
People who make use of assistive technologies are often vulnerable members of society; their use of assistive technologies is sensitive information about them. If an API provides access to this information without the user’s consent, this sensitive information may be revealed to others (including state actors) who may wish them harm.
Sometimes people propose features which aim to improve the user experience for users of assistive technology, but which would reveal the user’s use of assistive technology as a side effect. While these are well intentioned, they violate § 1.2 It should be safe to visit a web page, so alternative solutions must be found.
3 Comments
Thank you for the post, Adrian! This 6 years old post is the most complete I’ve found on the internet about this topic.
I came across this post while trying to figure out how to detect a screen reader so I could IMPROVE the experience for people using a screen reader, most of the website functions well and out of the box with the screen reader, except for one element (integrated facebook timeline on the website) which was highly requested by my client.
Another high request from my client is that the website is screen reader friendly, this particular client is a church.
The two requirements are in opposition to each other, so I have to find a suitable solution for this, using aria-hidden=”true” doesn’t solve the problem although it should.
The end game here is that it’s impossible to present a website that has a high standard of user friendliness for everyone. Making a site user friendly takes up time, someone has to pay people for the time they use on this, and not everyone has the money to throw at accessibility development because you want to help as many users as possible or you end up helping no one. It’s a compromise, not an action out of malice.
A website does not owe you anything, nor does a company, you are not entitled to have accessibility, living with a disability is a strain on other people whether we like it or not, and we have to accept that. People with a disability know and accept that there are things they cannot do in their life, and that’s fine.
When people to want to help, or when the requirement seems fit, the law of least resistance comes into play, if the work needed for a challenge isn’t beneficial for the person doing it, they are losing on it, nobody wants that, this is just human nature.
The poll you show also speaks for itself, the majority of people with disabilities don’t mind that websites know they have a disability. If you’re in a car in the real world, in a wheelchair, walk around with a cane that indicates you’re blind, people will also know, but most people will actually help you, why is this so different?
Just make it illegal to abuse it. It’s not going to be perfect, but as with everything in life, nothing is.
In response to . A website does not owe you anything, nor does a company, you are not entitled to have accessibility, living with a disability is a strain on other people whether we like it or not, and we have to accept that. People with a disability know and accept that there are things they cannot do in their life, and that’s fine.
I am guessing you do not have a disability and/or do not identify as being disabled (the latter representing people who have a disability but either do not understand it or are ashamed of it). If that is the case, then I am not sure speaking on behalf of the community is a good idea.
Just make it illegal to abuse it. It’s not going to be perfect, but as with everything in life, nothing is.
As Léonie Watson points out for accessibility work, you don’t need to be perfect on day one, you just need to be a little better than yesterday. I believe you have to actually try.
As for making it illegal, remember that the even ADA has no enforcement component. It requires people to bring claims. And it does not apply to the web. So
justmaking it illegal is not as easy a lift as you suggest.
Leave a Comment or Response