Stop Throwing Away Your Content
It is not uncommon for individuals and even entire organizations to rely on some third party platform to host all their thought-leadering. Medium is the common choice, but many use other platforms as well, such as LinkedIn.
While many argue that the reach is better and it is easier than self-hosting, few consider what will happen when their chosen platform goes away (or the platform chooses to purge you). After all, the web is littered with the corpses of platforms populated by content that you wrote and that we will never see again.
I'm not a betting man, but I'm willing to bet that publishing work *solely* on Medium is a mistake people will later regret doing.
When Medium does go away / pivot, history suggests your content will be lost with low odds you’ll get a data dump. twitter.com/stephenhay/status/7176
The Internet Archive’s Wayback Machine Will Not Save You
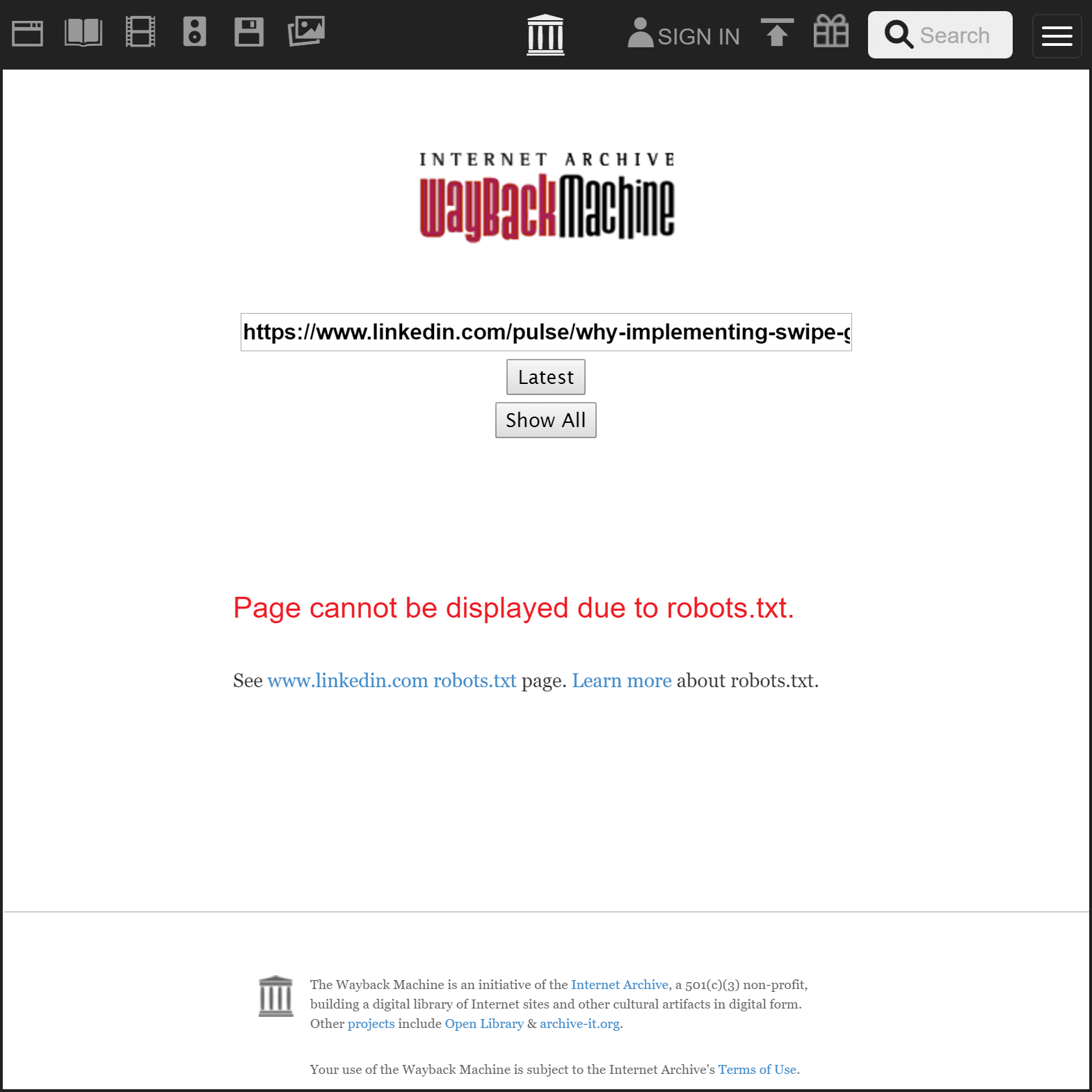
Page cannot be displayed due to robots.txt.
It is not uncommon for me to rely on the Internet Archive’s Wayback Machine to pull up an older version of a page or a site. I have posts on this site going back to 1999, and I can assure you that many resources that I linked have gone away since then so I rely on the Internet Archive to provide replacement links. Link rot is real.
I also sometimes create an archived snapshot of a page, particularly when I suspect the author may engage in some revisionist history.
The problem here is that the Internet Archive will de-list pages (or an entire site) with a simple robots.txt edit. This was particularly annoying to me when I found links to old Brighkite posts went away when the new domain owners excluded everything from the archive with a simple robots.txt entry.
I first mentioned this in 2013 when the U.K. conservative party effectively wiped ten years of speeches from the archive with a simple robots.txt edit. This was not a new tactic, the Internet Archive provides an overview in its legal section.
This means the Internet Archive will de-list historical pages, regardless of when you made any robots.txt file changes to block them.
The good news here is that when the new Brightkite domain owners removed the restrictions from its robots.txt, the old pages re-appeared in the Internet Archive — such as my old profile, for example. That means it is possible to restore de-listed pages.
Unfortunately, what we do not know is if the Internet Archive will fail to crawl any pages when the robots.txt file currently blocks them, meaning even if the robots.txt file changes to allow the Internet Archive crawler, any content prior to that change may be forever unarchived.
Update: January 20, 2017
The Internet Archive has stated that when archiving web sites at .mil and .gov top-level domains it will ignore robots.txt. On this U.S. inauguration day as the White House and other government web sites typically flip to reflect a new administration, you can still get to the history of the former administration’s site. While the prior administration’s sites are archived at their own domains, these archived sites still do not capture historic changes.
What to Do?
A good first step is to avoid any platform that will not allow itself to be archived by the Wayback Machine. You can do this by going to the Internet Archive and pasting the URL of any page from that platform. If you see the message Page cannot be displayed due to robots.txt,
then do not use that platform.
Remember, however, that a future owner of that site (or domain) can simply wipe all history from the Wayback Machine.
The best option is to self-host. I do not mean you have to set up a server. You can spin up a WordPress site, hosted for free, that you can then take with you should you want total control. Something like Wix or SquareSpace, however, I would not recommend. Their business model is all about the author interface, which means when their model changes they may not be willing to provide an easy migration off their platform.
Platforms to Avoid Now
I can name three platforms that you should probably just stop using (in favor of self-hosting). At some point they (or their posting feature) will probably go away and take your content with them.
Forgetting the incredibly confounding commenting model (as well as malformed infinite scroll and URL hijacking), LinkedIn explicitly blocks the Internet Archive crawler (here is an example).
LinkedIn does not need to go out of business (assuming its acquisition fails), all it needs to do is dump its Pulse feature or change the URLs to all of your content. Then all links pointing back to your content will break and users (including you) will be unable to use the Wayback Machine to find it.
If your content matters to you, I implore you to either stop publishing on LinkedIn immediately, or also make it available at a domain you control and promote that URL instead.
Authors, I implore you not to publish articles via @LinkedIn. When it dumps/moves URLs, your stuff will be lost. pic.twitter.com/iqcrmVllPt
Dear @LinkedIn, please allow @internetarchive access to content in Pulse so it can be archived when/if your business model/URLs change.
Update: August 15, 2016
With no clarity from LinkedIn on what it considers to be a bad bot (or scraper) in this lawsuit, it seems unlikely LinkedIn will allow the Internet Archive into anything in the /pulse URL path. Please just stop posting your original content to LinkedIn.
A LinkedIn representative declined to comment on how the company differentiates between good and bad scraping, referring TechCrunch to the complaint, which does not discuss how the company makes that determination.
Jelly
Jelly has just re-launched and is mostly following its old business model. Like Quora, it gathers lots of effort from its membership in the form of member answers to member questions.
The problem here is two-fold. First, for Jelly’s relaunch it dumped all the user-generated content it had in its initial version, and did it knowingly and unapologetically. Second, thanks to some terrible scripting, any pages for the new site effectively break within the Wayback Machine (see one in action).
@aardrian Hey. Sorry about the delay in response. Content didn't transfer to Jelly 2.0. We posted all that info in Jelly 1 :)
Also, something in @askjelly’s implementation breaks Wayback Machine (content flashes, then replaced by site 404): web.archive.org/web/20160707172751/https://askjelly
Quora
Quora may be the precursor to Jelly, but it follows the LinkedIn model of explicitly banning any archiving via its robots.txt file, and provides the following explanation within the file itself:
People share a lot of sensitive material on Quora – controversial political views, workplace gossip and compensation, and negative opinions held of companies. Over many years, as they change jobs or change their views, it is important that they can delete or anonymize their previously-written answers.
We opt out of the wayback machine because inclusion would allow people to discover the identity of authors who had written sensitive answers publicly and later had made them anonymous, and because it would prevent authors from being able to remove their content from the internet if they change their mind about publishing it. As far as we can tell, there is no way for sites to selectively programmatically remove content from the archive and so this is the only way for us to protect writers. If they open up an API where we can remove content from the archive when authors remove it from Quora, but leave the rest of the content archived, we would be happy to opt back in. See the page here:
The argument is compelling, but given that Quora mostly wants you to log in to view its content (to monetize you) you can probably just dismiss it. If Quora should decide the answer I just linked does not paint it in the best light and then deletes it, you will not be able to get an archived version either.
Update: December 16, 2018
In the post Why You Should Never, Ever Use Quora, Andy Baio points out pretty much everything I outline above and reminds us that 100 million user account were compromised, including direct messages and other activity.
Medium (as of January 4, 2017)
It looks like Medium is making some changes:
As of today, we are reducing our team by about one third — eliminating 50 jobs, mostly in sales, support, and other business functions. We are also changing our business model to more directly drive the mission we set out on originally.
[…]
To stay efficient, we are shutting our offices in New York and Washington D.C. (though some people will continue to work remotely from those locales). And we will be parting ways with some of our executives who were brought on to scale these teams.
This does not necessarily mean that Medium is going away, but history suggests that when start-ups with no path to profitability lay off staff, close offices, and change their business model, things generally do not get better.
As such, I feel that this tweet is more relevant today:
When Medium shuts down we're gonna lose SO many posts about other startups shutting down
Update: January 5, 2017
Thanks to the Twitters, I was reminded that Medium has a page showing you how to export your content. I made a WayBack archive of the page, though if this tutorial on Medium goes down then Medium itself might be down and you won’t be able to export anyway.
Update: March 26, 2017
The support article telling users how to export content from Medium (that I linked above) has gone away. It is 404. No redirection, no help, just gone. I found another page which, while it outlines the same process, is far less detailed. Almost like Medium wants to make it less easy. As with the link above, I also saved it to the WayBack archive. After all, there is clearly no guarantee it will stay up at Medium.
Update: August 25, 2017
The article talks AMP, but if iOS11/Safari leans on canonical URLs (yay!) on shares, then impacts Medium as well: https://www.theverge.com/2017/8/23/16193584/ios-11-safari-google-amp-sharing-url-scheme
Update: January 10, 2018
Tim gets it.
I wrote 17 posts for the Snyk blog and a handful of posts for other sites as well. I posted 889 tweets to Twitter. I reviewed 47 books on Goodreads. I’m probably forgetting some other things.
But here, on my own site? Four. I wrote four posts. For someone who loves to talk about how important it is to own your own content and to write for yourself, I’ve done precious little of that as of late.
Update: September 5, 2018
Medium is no longer offering custom domains. Existing custom domains will be kept for the foreseeable future
, which is meaningless.
Medium is no longer offering new custom domains as a feature. Instead, you can create a publication on Medium that will live on a medium.com/publication-name URL.
If you are thinking of making a place for your writing for your brand (you, your organization, whatever), and you still thought Medium was an option, then stop. You have no control and when Medium does go away you cannot even reclaim the URLs (to redirect them) since you do not own the domain.
Update: December 5, 2018
I also wish more people blogged on their own site.
I wish more people blogged on their own site instead of on Medium. The experience on Medium is so poor these days with pop-ups and “you’ve reached your 3 articles”.
Update: April 5, 2019
Sara Soueidan’s response on why to move away from Medium is on point:
– You own your content.
– You express your brand and personality in the design.
– My site is my creative & experimemtal playground for all things cutting edge.
– RSS to keep up w/content outside Twitter noise.
– You own your own content. Forever. twitter.com/hemeon/status/1114
Update: November 30, 2022
Now that Twitter is eating itself, you may want to grab your Twitter archive. Understand, though, that it will not include the alternative text you provided for your images nor the closed captions you provided for your videos. Two services that can help on the former:
Understand these locally-run scripts will have access to your entire archive.
Tweetback will create a browseable version of your archive that does away with the t.co links. It does not appear to handle alternative text.
7 Comments
I’ve been trying to convince people to do this for a while now. If you feel that you get more exposure through LinkedIn, Medium, Google+ etc then by all means publish there…. but make it a syndication publication rather than only publishing on those platforms.
With regards to your comments about WordPress, there’s some plugins that will auto post to Medium when you publish to your own site and even top/tail it with links back to the original for example Original vs Syndicated
In response to . I fully support any plug-in that sets the canonical link in the Medium post back to your own self-hosted post. Care to share what plug-in you used (for those who may want to know and are not as technical to know to look for the canonical bits)?
re: “(a) plug-in that sets the canonical link in the Medium post back to your own self-hosted post.”
Looks like Medium itself has directions, along with a WP plugin, to do this…
Near the bottom: “Cross-posting, syndication, and canonical URLs”
https://help.medium.com/hc/en-us/articles/218572107-How-to-move-to-Medium
In response to . Nice! I never looked, but I hope those that use Medium as a platform take advantage of that.
[…] the growing number of third-party platforms vying to be the primary place to publish your content, a word of caution and reminder that no platform is forever. Own your own […]
I publish on my own blogs, shared them to social network, and spread them hope more people share my blogs, aims to attract more people to my shopping site. I always believe that content is king to SEO.
If you want to be really scared, take a look at https://indieweb.org/site-deaths
Leave a Comment or Response